
TL;DR:
- Measurable service quality uses standardized tools like SERVQUAL, CSAT, and NPS to assess how well a service meets or exceeds customer expectations. Building effective programs involves defining standards, strategic sampling, and continuous systemic improvements based on data insights. Success depends on closing feedback loops across organizational silos, combining qualitative and quantitative metrics, and treating quality as an organizational priority for ongoing business improvement.
Measurable service quality is the objective evaluation of how well a service meets or exceeds customer expectations, using standardized tools and metrics to quantify both customer perceptions and operational performance. Industry expert Mark Howell defines it as the perceived difference between expected and delivered benefits, shaping whether customers feel satisfied or disappointed. The standard industry term for this practice is service quality measurement, and it sits at the center of every high-performing customer experience program. Tools like the SERVQUAL model, Customer Satisfaction Score (CSAT), and Net Promoter Score (NPS) give business leaders a structured way to move beyond gut feeling and into data-driven decisions. A Deloitte study confirms that companies actively measuring customer satisfaction achieve higher customer experience scores, which translates directly into retention and revenue.
What is measurable service quality and how is it structured?
The two most widely applied frameworks for breaking service quality into measurable dimensions are SERVQUAL and the RATER model. SERVQUAL measures service quality by capturing the gap between customer expectations and perceptions across five dimensions, developed in the 1980s and applied across sectors including healthcare, banking, and retail. Understanding these dimensions is the first step toward building a measurement program that actually reflects customer reality.
The five SERVQUAL dimensions are:
- Reliability: The ability to deliver the promised service accurately and consistently
- Assurance: The knowledge and courtesy of employees, and their ability to convey trust
- Tangibles: The physical facilities, equipment, and appearance of personnel
- Empathy: The degree of caring and individualized attention provided to customers
- Responsiveness: The willingness to help customers and provide prompt service
The RATER model is a practical variation of SERVQUAL that reorganizes the same five dimensions under the acronym Reliability, Assurance, Tangibles, Empathy, and Responsiveness. Both models capture customer perceptions systematically, but RATER is often preferred in training contexts because the acronym makes it easier for frontline teams to internalize and apply.
| Dimension | SERVQUAL focus | RATER application |
|---|---|---|
| Reliability | Consistent, accurate delivery | Core operational standard |
| Assurance | Trust and competence signals | Agent training priority |
| Tangibles | Physical or digital environment | Interface and environment design |
| Empathy | Personalized care | Customer-facing tone guidelines |
| Responsiveness | Speed and willingness to help | SLA and queue management |

The gap these models measure is not just academic. When a customer expects a 24-hour resolution and receives a 72-hour one, that gap registers as a quality failure regardless of how efficiently the team operated internally. Closing that gap requires knowing exactly where it exists, which is why these frameworks remain foundational to evidence-based service quality programs.
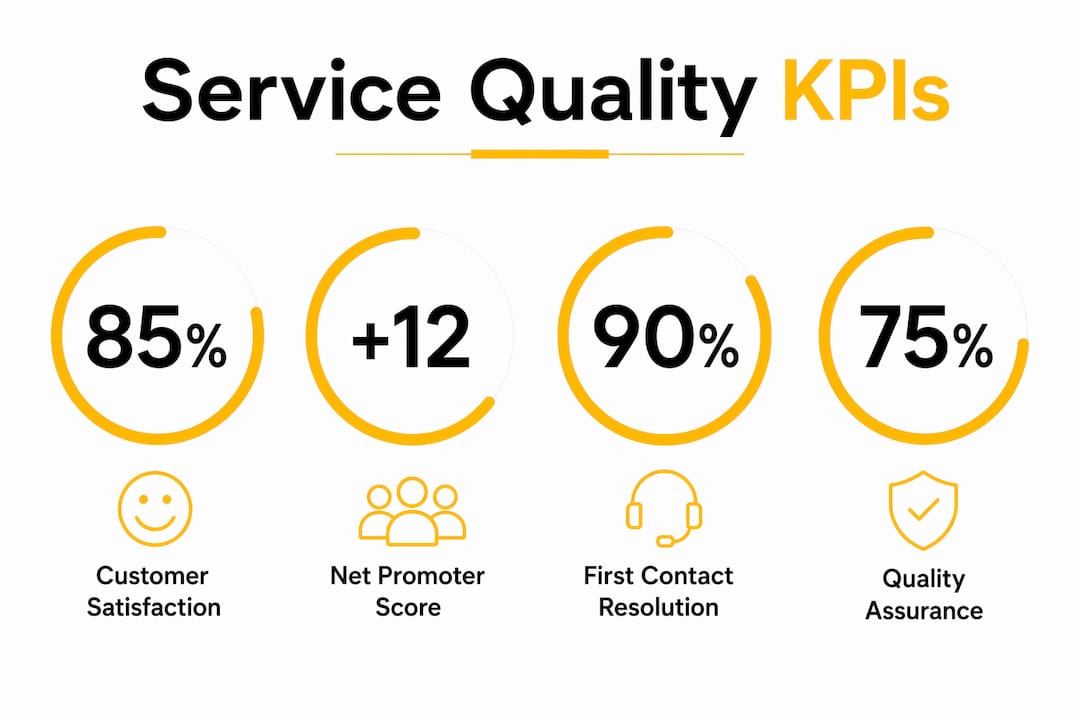
Which KPIs quantify service quality most effectively?
Knowing which metrics to track separates organizations that manage service quality from those that only monitor it. Standard service quality metrics include NPS (scored from -100 to +100), CSAT (scored 1 to 5), Customer Effort Score or CES (scored 1 to 7), and the RATER dimensions. Each metric captures a different layer of the customer experience.
Here is what each metric actually measures and why it matters:
- NPS tracks customer advocacy by asking how likely a customer is to recommend your company. It effectively tracks advocacy while revealing long-term loyalty trends across your customer base.
- CSAT gauges immediate satisfaction after a specific interaction. It is the fastest signal for identifying whether a single touchpoint succeeded or failed.
- CES estimates the effort a customer expended to reach their goal. High effort scores predict churn more reliably than low satisfaction scores in many B2B contexts.
- First Contact Resolution (FCR) measures whether a customer’s issue was resolved in a single interaction. High FCR correlates directly with lower handling costs and higher CSAT.
- Average Handle Time (AHT) tracks the average duration of customer interactions. AHT is useful as a capacity metric but becomes misleading when used as a quality proxy in isolation.
The real power comes from combining these metrics rather than relying on any single number. NPS tells you where loyalty stands. CSAT tells you where specific interactions broke down. CES tells you where your processes create unnecessary friction. FCR and AHT tell you whether your operations support or undermine the customer experience. Together, they give you a 360-degree view of service effectiveness.
Pro Tip: Pair every quantitative metric with a qualitative data source. Post-interaction surveys, verbatim customer comments, and call recordings reveal the “why” behind the numbers that scores alone cannot explain.
How do organizations build a sustainable quality assurance program?
Quality assurance (QA) in customer service is the systematic evaluation of customer interactions against defined standards, with the goal of identifying gaps and driving improvement. Modern QA transforms support centers from cost centers into revenue-retention engines by analyzing conversation substance rather than volume alone. Building a program that sustains results over time requires a deliberate, step-by-step approach.
-
Define your quality standards. Start by documenting what a high-quality interaction looks like for your organization. This includes tone, accuracy, resolution rate, compliance requirements, and empathy markers. Standards must be specific enough to evaluate objectively.
-
Design a binary scorecard. Static scorecards reduce measurement effectiveness. Use 4 to 6 focused, weighted categories with yes/no scoring to keep evaluations objective and consistent across reviewers. Questions like “Did the agent confirm the customer’s issue before responding?” eliminate subjective interpretation.
-
Select your sampling strategy. Best practice QA programs sample 5 to 10% of agent conversations and include monthly coaching sessions of 30 to 60 minutes. Random sampling provides a baseline, but targeted sampling focused on low-CSAT interactions, escalations, and long handle times surfaces the critical failures that random pulls miss.
-
Calibrate your evaluators. Calibration sessions, where multiple reviewers score the same interaction independently and then compare results, prevent scoring drift. Without calibration, QA scores reflect reviewer bias as much as agent performance.
-
Coach based on data, not impression. Every QA finding should connect to a specific coaching conversation. Agents need to see the interaction, hear the feedback, and understand the standard they missed. Coaching sessions grounded in recorded evidence are significantly more effective than general performance discussions.
-
Close the feedback loop at the system level. Closing the feedback loop by updating training materials, knowledge bases, and workflows based on QA data maximizes service quality improvements. If ten agents make the same mistake, the problem is the process, not the people.
Pro Tip: Review your scorecard every quarter. Customer expectations shift, products change, and a scorecard built for last year’s service model will measure the wrong things this year.
For teams building these programs from scratch, a customer service checklist can help structure the initial rollout and prevent common gaps in coverage.
What challenges affect the accuracy of service quality data?
Measuring service quality is not simply a matter of deploying a survey or running a QA scorecard. Several structural and interpretive challenges can distort the data and lead to decisions that make things worse, not better.
The most common pitfall is confusing volume metrics with quality metrics. Tracking the number of tickets closed or calls handled tells you about throughput. It says nothing about whether customers left those interactions satisfied. Targeted sampling focused on low CSAT scores, escalations, and long handle times finds critical service failures that random sampling misses entirely. Volume metrics have their place in capacity planning, but they cannot substitute for substantive quality evaluation.
Context also shapes how KPIs should be interpreted. A high AHT in a technical support environment may reflect thorough, high-quality troubleshooting. The same AHT in a billing inquiry context signals inefficiency. Applying uniform benchmarks across different interaction types produces misleading conclusions.
“Effective service quality programs require interdisciplinary collaboration integrating marketing, human resources, and operations management to embed the customer perspective across the organization.” — Service Quality, Schneider & White, Sage Publications
This insight matters because service quality failures rarely originate in a single department. A confusing product description created by marketing leads to a spike in support contacts. A poorly designed onboarding workflow built by operations creates friction that no amount of agent coaching can fix. Measuring service quality accurately requires breaking down the silos between teams that influence the customer experience, even when they never speak directly to a customer.
How does quality data drive continuous improvement and business outcomes?
Data collected from CSAT surveys, NPS tracking, QA scorecards, and FCR reports is only valuable when it drives decisions. The organizations that improve fastest treat their quality data as a diagnostic tool, not a report card.
When QA data reveals that a specific product category generates disproportionate escalations, the right response is to update the knowledge base, revise the agent training module for that category, and monitor whether the escalation rate drops. That is a systemic fix. Ongoing systemic fixes outperform solely coaching individuals, because they address the root cause rather than the symptom.
The business outcomes from this approach are concrete. Quality consistency reduces churn, with one 2025 Rocketlane report showing a 53.5% reduction in churn when early standardized interactions were smooth and QA-backed. NPS scores improve when agents receive targeted coaching on the specific behaviors that drive customer advocacy. Handling time decreases when knowledge bases are updated based on the questions agents most frequently struggle to answer.
| Metric | Before QA adoption | After QA adoption |
|---|---|---|
| CSAT score | 3.2 / 5 | 4.4 / 5 |
| NPS | +12 | +41 |
| First Contact Resolution | 61% | 78% |
| Average Handle Time | 9.4 minutes | 7.1 minutes |
| Customer churn rate | 18% | 11% |
These numbers reflect the compounding effect of a well-designed measurement program. Each metric improvement reinforces the others. Higher FCR reduces AHT. Lower AHT frees capacity for more thorough interactions. More thorough interactions drive CSAT and NPS upward. Understanding why service quality measurement produces these compounding returns is what separates leaders who invest in QA from those who treat it as overhead.
Key takeaways
Measurable service quality requires combining structured frameworks like SERVQUAL with KPIs such as CSAT, NPS, and FCR, then using QA programs to close the gap between customer expectations and actual delivery.
| Point | Details |
|---|---|
| Use SERVQUAL or RATER as your foundation | These frameworks break service quality into five measurable dimensions that capture customer perception systematically. |
| Combine quantitative and qualitative metrics | CSAT, NPS, and CES each measure different layers; pair them with verbatim feedback for complete insight. |
| Sample strategically, not just randomly | Target low-CSAT interactions and escalations to surface systemic failures that random sampling misses. |
| Close the loop at the system level | Update knowledge bases, workflows, and training based on QA data rather than only coaching individual agents. |
| Treat measurement as an ongoing discipline | Static scorecards and one-time audits degrade in value; review and adapt your program every quarter. |
What I have learned from watching quality programs succeed and fail
By Daniela
Most organizations launch a QA program with genuine intent and then quietly let it drift into a compliance exercise. Scorecards get filled out. Coaching sessions happen. And yet service quality stays flat. The reason, almost every time, is that the feedback loop never closes at the system level.
I have seen teams spend months coaching agents on the same issue, only to discover that the root cause was a knowledge base article written three years ago that gave agents the wrong information. No amount of individual coaching fixes a broken process. The measurement data was pointing at the symptom. Nobody looked upstream for the cause.
The other pattern I consistently observe is an over-reliance on random sampling. Random sampling protects against bias in performance reviews, and it has its place. But if you want to find where your service model is breaking down, you need to look at the interactions where customers were most frustrated. Low-CSAT scores, escalations, and unusually long handle times are signals, not noise. Treat them as a diagnostic map.
Service quality measurement is not a function that belongs to the QA team alone. It is an organization-wide priority that requires marketing, operations, HR, and leadership to act on what the data reveals. The companies that get this right do not just measure better. They build a culture where quality data changes decisions at every level.
— Daniela
How Altiam CX helps you build a measurable quality program
Altiam CX partners with business leaders who need more than a measurement framework. They need a team that executes it consistently, at scale, across every customer interaction. Altiam CX’s nearshore customer experience model combines disciplined QA programs, cultural alignment, and performance analytics to give organizations real-time visibility into service quality. One software platform that migrated its tech support operations to Altiam CX saw productivity improve by 89%, with measurable gains in resolution rates and customer satisfaction. If you are ready to move from tracking quality to actually improving it, explore Altiam CX’s CX solutions to see how a structured, nearshore approach delivers results your current model cannot.
FAQ
What is measurable service quality?
Measurable service quality is the objective evaluation of how well a service meets customer expectations, using standardized tools like SERVQUAL, CSAT, NPS, and QA scorecards to quantify both customer perceptions and operational performance.
What are the five dimensions of SERVQUAL?
The five SERVQUAL dimensions are reliability, assurance, tangibles, empathy, and responsiveness. Each dimension captures a different aspect of how customers perceive service delivery relative to their expectations.
How do you assess service quality step by step?
Start by defining quality standards, then design a binary scorecard, select a sampling strategy covering 5 to 10% of interactions, calibrate evaluators, coach agents based on findings, and update workflows and knowledge bases to close systemic gaps.
What is the difference between CSAT and NPS?
CSAT measures immediate satisfaction after a specific interaction on a 1 to 5 scale, while NPS measures long-term customer advocacy on a scale from -100 to +100. Both metrics serve different diagnostic purposes and work best when used together.
Why does targeted sampling outperform random sampling in QA?
Targeted sampling focused on low-CSAT scores, escalations, and long handle times surfaces critical service failures that random sampling statistically misses. It identifies systemic problems faster and directs coaching resources where they produce the greatest impact.


